The definitive guide to load balancers.
A complete guide to load balancers in distributed systems.
Load balancers are an extremely important topic in distributed systems. They are used in almost every large scale system. Keep reading to know what they are and understand how they works.
Introduction
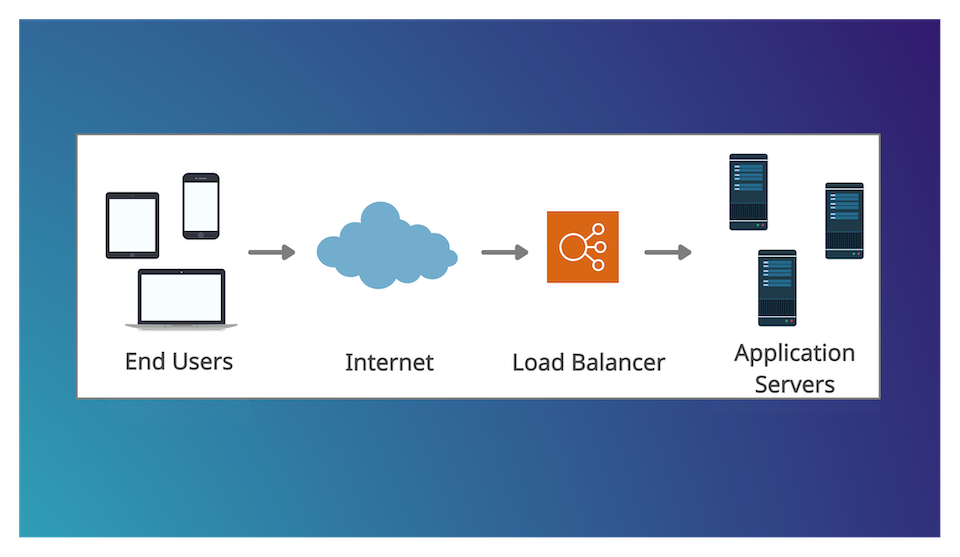
Let's start with a simple use case where we have a client issuing requests to server. The server performs some business logic, fetch some data from a database and then returns responses to the client.
All works fine, but what happens if the system becomes bigger?
Let's say we have now N clients issuing multiple requests. The server has limited resources and throughput.The more requests the server receives the more it get overloaded. Our system becomes soon very slow or even worst a failure happens.
How can we prevent this?
Of course we can scaling our system. There are 2 possibilities:
- vertical scaling, increasing the power of the server;
- horizontal scaling, adding more servers.
The problem of vertical scaling is that it is limited by the maximum amount of resources a single server can have. At a certain point we need to scale horizontally.
Teoretically, if we add M servers having the same resources, the system can handle M times the initial load. But this is true only if the requests of the client are equally distributed across the servers. Here is exactly where the load balancer comes into play.
Definition
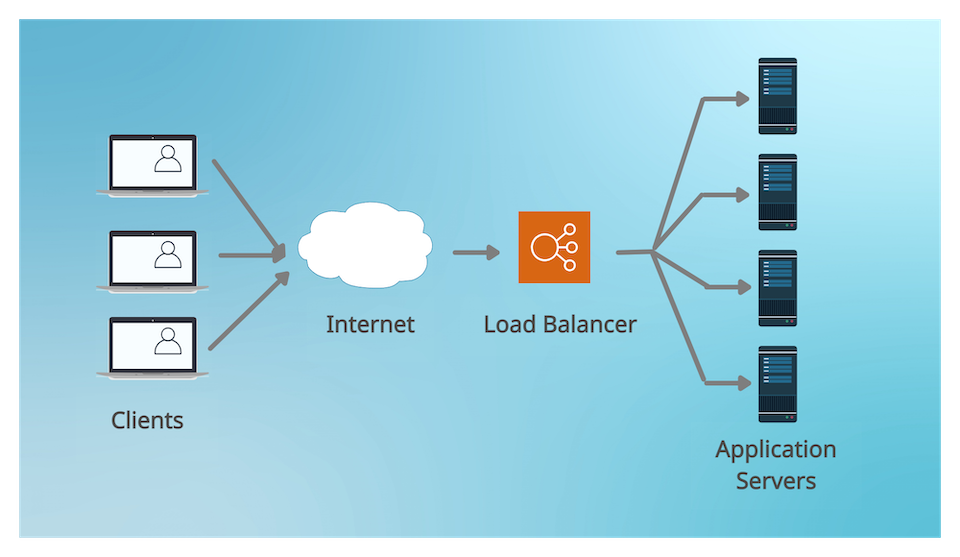
A load balancer is a server sitting between a set of clients and a set of servers and performing the job of balancing the clients requests between the servers. It acts as a reverse proxy, redirecting and distributing the requests from the clients to the servers.
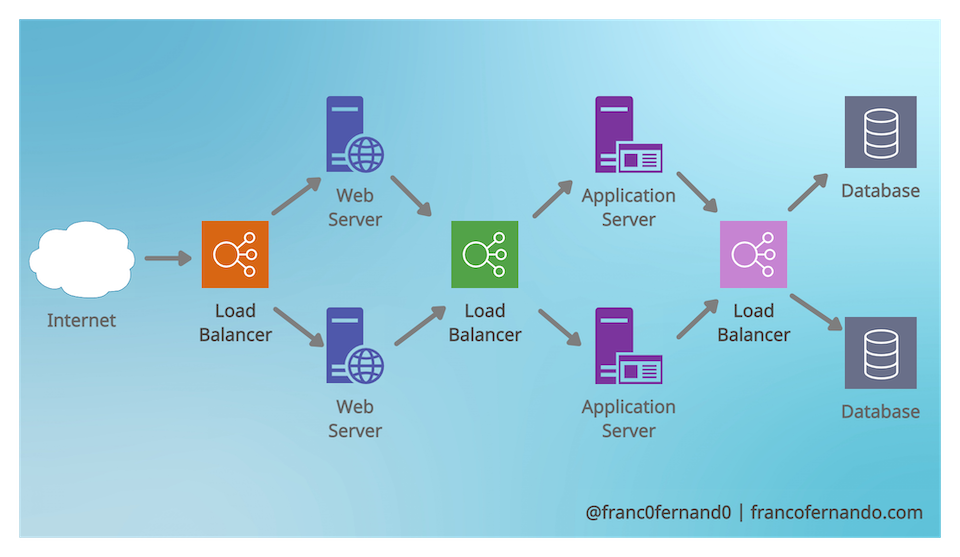
Load balancers can be placed not only between clients and servers, but in many other different places of a system like between servers and databases or at DNS layer when dealing with web servers.
There are different types of load balancers and multiple way to categorize them.
Hardware and Software Load Balancers
A first categorization distinguishes between hardware and software load balancers.
Hardware load balancers are high-performance devices able to process high traffic from many kind of applications. They can also have the capabilities to support virtual load balancers instances on the same hardware.
They are efficient, but also expensive. Popular vendors are Citrix or Radware.
Layer 4 and Layer 7 Load Balancers
A second categorization distinguishes between Layer 4 and Layer 7 load balancers, according to the network layer where they act.
Layer 4 load balancers redirect traffic based on the TCP or UDP ports of the packets along with their source and destination IP addresses. Instead, layer 7 load balancers redirect traffic inspecting the actual content of each packet, including HTTP headers and SSL session IDs.
Servers selection strategies
There are still two important questions to answer. The first one is how a load balancer knows to which servers distribute the traffic. The second one is how a load balancer distributes the requests to the servers.
The first question is easier to answer. The system administrators configure load balancers and servers to know about each others. When they add or remove a new server, this is registered or deregistered with the load balancer.
The second question is more complex. There are many different server selection strategies. Let's revise the most popular ones.
Random redirection: the load balancer redirects the traffic to the servers following a pure random order. This strategy could have problem because a server can get overloaded by chance.
Round Robin: the load balancer evenly redirects the traffic to the servers following a certain circular order. A variant is the weighted Round Robin where each server receives a number of requests according to a given weight. This can be useful if some servers are more powerful than others.
Performances based redirection: this is a more involved approach. The load balancer performs healthy checks on the servers to get statistics like how much traffic they are handling any given time or how long they take to answer or how many resourcers they are using. The load balancer redirects the traffic according to this information. If the load balancer gets to know that a server is doing poorly, it stops redirecting request to that server. Instead if the load balancer notices that a server is not overloaded and performs well, it redirects more traffic to it.
IP based redirection: the load balancer calculates a hash of the client's IP address and redirects the traffic according to the value of the hash. This can be useful if the server caches the results of the requests. Why? Becaues all the requests of the same client are always redirected to the same server in which the responses of the particular client has been cached. So cache hits get maximized.
Path based redirection: the load balancer distributes requests according to their URL. Why can this be useful? All the requests for a service are redirected to a specific set of servers. This separates the services making easier the deployment and isolating them in case of failures.
You could now wonder which strategy is better. The answer is no one. Each strategy has advantages and disadvantages and it's always wise to select the best strategy fitting your use case. In absence of clear requirements, Round Robin is always a good strategy to start with.
It can also make sense to have multiple layers of load balancer adopting different strategies. The load balancer in the first layer redirects the traffic to the load balancer in the second one that then redirects the traffic to the servers. For example the first layer could use the hash and second the Round Robin.
Redundancy
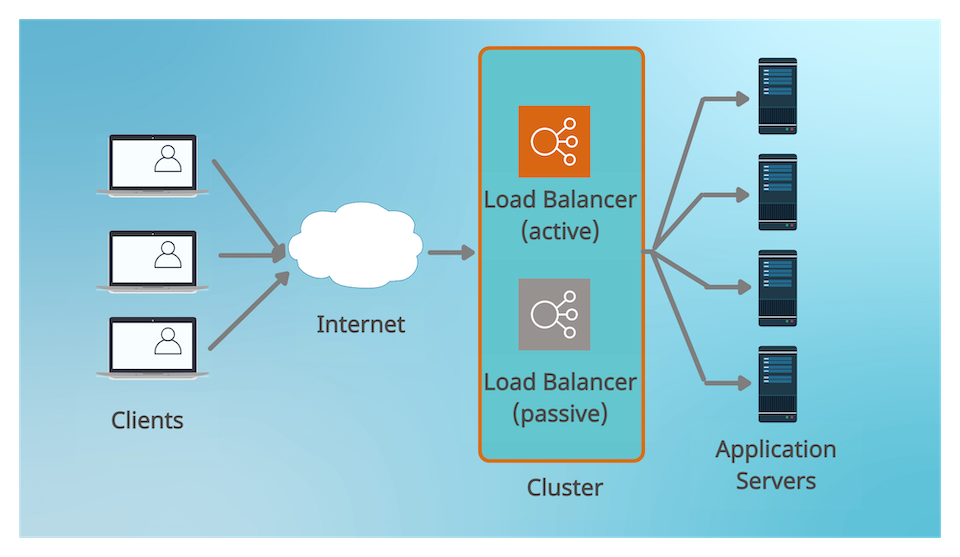
Load Balancers can be single points of failure in a system. If you have a single load balancer and this gets overloaded or fails, the whole system goes down.
In order to prevent this, multiple replicas of the load balancer are usually connected into a cluster. Each replica monitors the healthy of the others. In case the main load balancer fails, another replica takes over and starts rerouting the traffic.
Advantages
These are the most straightforward advantages you can get introducing the use of load balancers while designing your system:
Optimizing the use of resources by distributing clients requests across servers
Improving the user experience by ensuring a faster response time
Preventing system downtime by rerouting requests from overloaded/failed servers to healthy ones
Giving more flexibility in adding/removing servers and performing server maintenance
Introducing more redundancy and resilience into the system
Clustering
Load balancing shares common traits with clustering but there is a main difference. Servers in a cluster are aware of each other and work toward common purpose. Load balanced servers just react to commands from LB and don't know about each other.
Conclusion
Load balancers are a key component of any distributed system and can be extremely useful while designing a system. They can be placed in many place of a system, increasing its flexibility, improving its performances and making it more robust. I hope this post helped you in understanding better what load balancers are, what are the different kind of load balancers and how you can use them while designing a system.
If you liked this post, follow me on Twitter to get more related content daily!