How to efficiently compare strings with rolling hash
This post explains in details the Rolling Hash technique and how it can be used to efficiently compare strings.
Hashing algorithms are useful to solve a lot of problems. In this post we will discuss the rolling hash, an interesting algorithm used in the context of string comparison.
The idea is to have a hash function computed inside a window that moves through the input string. When the window moves, this hash function can be updated very quickly without rehashing the whole window using only:
- the old hash value;
- the old character removed from the window;
- the new character added to the window.
Let's see how this works under the hood using a specific class of hash functions known as polynomial hash.
Polynomial Hash Function Permalink
Given an input string s of length n, we can compute its polynomial hash with multiplications and additions according to the following formula:
where b is a constant positive number. Since all the characters in the input alphabet can be reduced to a positive number between 0 and the size of the alphabet, this formula is equivalent to interpret the string s as a number in a numeral system with base b.
It is reasonable to chose b as the first prime number greater or equal to the number of characters in the input alphabet. The choice of a prime number will guarantee a more uniform distribution of the keys and a lower number of collisions, regardless the nature of the input strings.
For example if the input is composed of only lowercase letters of the English alphabet, we can take b=31. With this choice the string bus has the following polynomial hash:
A naive implementation computing the polynomial hash of a string s is the following (the reverse iteration is for consistency with the formula):
int hash(string const& s) {
const int b = 31, m = 1000000009;
int h = 0;
int b_pow = 1;
for (auto it = s.crbegin() ; it != s.crend(); ++it) {
//Converting a to 0 the hashes of the strings a, aa, aaa
//all evaluate to 0, so add 1
h = (h * b_pow) + (*it - 'a' + 1);
b_pow *= b;
}
return h;
}
Modular Arithmetic and Horner's Rule Permalink
Calculating a polynomial hash function naively has two major drawbacks:
- accuracy, since manipulating large powers of b can cause integer overflow;
- inefficiency, since each character requires two multiplications and one addition.
The risk of integer overflow can be removed using modular arithmetic and performing all operations modulo M. According to the principles of modular arithmetic
we can rewrite the implementation of the polynomial hash as follow:
int hash(string const& s) {
const int b = 31, M = 1000000009;
int h = 0;
int b_pow = 1;
for (auto it = s.crbegin() ; it != s.crend(); ++it) {
//Converting a to 0 the hashes of the strings a, aa, aaa
//all evaluate to 0, so add 1
h = ((*it - 'a' + 1) + h * b_pow) % M;
b_pow = (b_pow * b) % M;
}
return h;
}
Clearly, the value of M shall be large enough to reduce the number of hash collisions. To have a better distribution of the keys, it is usually reasonable to chose M as a large prime number.
The efficiency of the computation can be improved using the Horner’s rule, a popular method that simplifies the evaluation of a polynomial of degree n by dividing it into n monomials (polynomials of degree 1). With the Horner’s rule the polynomial hash formula can be written as
and evaluated with only n multiplications and n additions. This is optimal, since a polynomial of degree n that cannot be evaluated with fewer arithmetic operations.
Using the Horner's rule with modular arithmetic, the polynomial hash of a string s can be computed as follows:
int hash (string const& s) {
const int b = 31, M = 1000000009;
int h = 0;
for (char c : s) {
h = (h*b + (c-'a'+1)) % M;
}
return h;
}
Rolling Hash Permalink
Let's now consider a sliding window of length 3 inside the string "business" and let's suppose that we already computed the hash value inside the starting window "bus". If the window move one position to the right, how can we generate the hash for the substring "usi" in constant time? The only changes from one window to the next one are the removing of the first letter 'b' and the adding of the last letter 'i'.
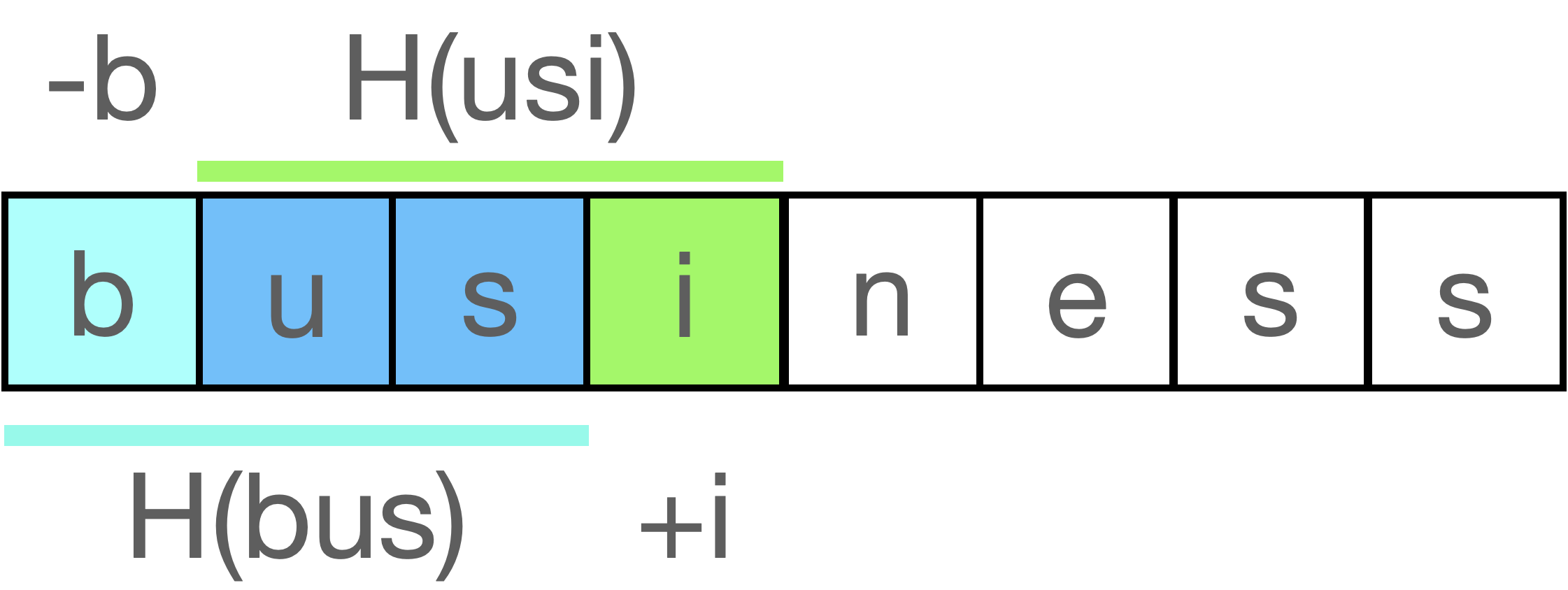
In terms of polynomial hash function this means:
Generalizing, we can get the new hash by
- subtracting the removed character to the old hash value:
- multiplying the updated hash value for b, so that each remaining character has the right power of b
- adding the next character
int roll (string const& s, int previousHash, char prevChar, char nextChar, int bPow, int M) {
previousHash -= (bPow * prevChar - 'a') % M;
previousHash *= bPow;
previousHash += (nextChar - 'a');
return previousHash;
}
Rabin Karp Algorithm Permalink
The most known application of the rolling hash is the Karp-Rabin algorithm which solves the following problem: given two strings, a text t and a pattern p, determine whether p appears in t. The brute force solution is straightforward: for every position in t, consider it as a starting position of p and check if we get a match.
bool bruteForce(string const& text, string const& pattern) {
for (int i = 0; i < text.size(); i++) {
for (int j = 0; j < pattern.size() && (i + j) < text.size(); j++) {
// mismatch found, break the inner loop
if (text[i + j] != pattern[j]) break;
// match found
if (j == pattern.size()-1) return true;
}
}
return false;
}
This approach is easy to understand and implement but it is too slow since it takes in the worst case O(T*P) time, where T is the length of the text and P the length of the pattern.
The Karp-Rabin algorithm uses a more efficient approach based on hash functions. The idea is to calculate a hash value for the pattern p and for every substring of length P in the text t.
Every time we find a substring with the same hash value of p, we have a candidate that can match the pattern. We can then compare the candidate substring with the pattern character by character to see if they are exactly equal. The reason why we can't say immediately that a substring with the same hash value of t is a match are of course the aforementioned hash collisions or spurious hits.
Notice how this algorithm is very similar to the brute force, but it doesn't always require the second loop that will be necessary only when the hash values of p and the current substring of t are equal.
Of course the approach described so far would be absolutely useless if we were not able to calculate the hash value for every substring of length P in t with just one pass through the entire text. Here is where the concept of rolling hash comes in handy.
bool rabinKarp(string const& text, string const& pattern) {
const int T = text.size(), P = pattern.size();
if (T < P) return false; // no match is possible
const int b = 31, M = 1000000009;
// calculate the hash value of the pattern
int hp = 0;
for (char c : s) hp = (hp*b + (c-'a'+1)) % M;
// calculate the hash value of the first substring of length P
int ht = 0;
for (i = 0; i < P; i++) ht = (ht*b + (text[i]-'a'+1)) % M;
// check character by character if the first substring matches the pattern
if (ht == hp && text.compare(0, P, pattern)) return true;
// start the rolling hash
for (i = m; i < n; i++) {
ht = (ht - (text[i - m] * bPow)) % M;
ht = (ht * B) % M;
ht = (ht + text[i]) % M;
if (ht == hp && text.compare(i-m+1, P, pattern)) return true;
}
return false;
}
With a good polynomial hash function (in terms of b and M parameters) and using the rolling hash technique, the time complexity of the algorithm becomes O(P+T) in average.
Unfortunately, there are still cases when we will need to execute the character by character for each substring of the text (i.e. searching p = “aaa” and t = “aaaaaaaaaaaaaa”).
The way to overcome this problem is the so called “double hash” technique. We compute for every substring two independent hash values based on different numbers b and M. If both are equal, we assume that the strings are identical without even executing the character by character comparison. Also “triple hash” could be teoretically used, but the likelihood of a spurious hit with the double one is so small that this is never necessary in practice.
Conclusion Permalink
The rolling hash technique is an important weapon for multi-pattern string search where we have to look at all substrings of fixed length of a given text or we want to find the most frequent substring of a fixed length in a given text.
One of its most known application is the Rabin-Karp algorithm, which can for example be used to detect plagiarism in text files.
Another context wher rolling hashing is extremely useful is data compression. In the LZ family of compressors we need to replace a previously occurred string by an offset to the previous position and a length, codified in several different forms. Using a rolling hash and storing the results and offsets, we don't need to scan all the text multiple time to detect repetitions.
If you liked this post, follow me on Twitter to get more related content daily!